Misalignment of LLM-Generated personas with human perceptions in low-resource settings
Tabia Tanzin Prama, Christopher M. Danforth, and Peter Sheridan Dodds
Times cited: 1
Abstract:
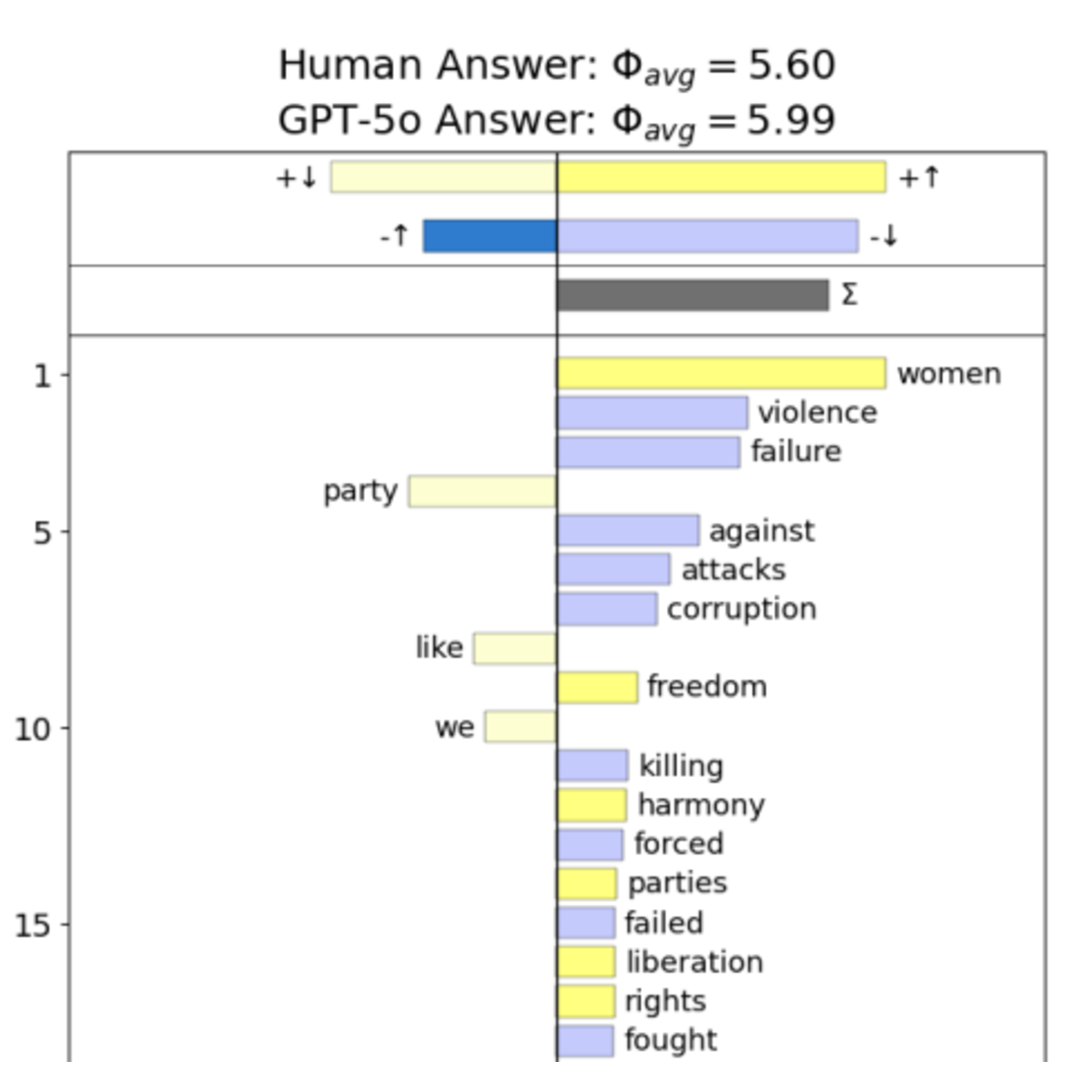
Recent advances enable Large Language Models (LLMs) to generate AI personas, yet their lack of deep contextual, cultural, and emotional understanding poses a significant limitation. This study quantitatively compared human responses with those of eight LLM-generated social personas (e.g., Male, Female, Muslim, Political Supporter) within a low-resource environment like Bangladesh, using culturally specific questions. Results show human responses significantly outperform all LLMs in answering questions, and across all matrices of persona perception, with particularly large gaps in empathy and credibility. Furthermore, LLM-generated content exhibited a systematic bias along the lines of the "Pollyanna Principle", scoring measurably higher in positive sentiment ( for LLMs vs. for Humans). These findings suggest that LLM personas do not accurately reflect the authentic experience of real people in resource-scarce environments. It is essential to validate LLM personas against real-world human data to ensure their alignment and reliability before deploying them in social science research.
- This is the default HTML.
- You can replace it with your own.
- Include your own code without the HTML, Head, or Body tags.
BibTeX:
@article{prama2025d,
author = {Prama, Tabia Tanzin and Danforth, Christopher M. and
Dodds, Peter Sheridan},
title = {Misalignment of {LLM}-generated personas with human
perceptions in low-resource settings},
year = {2025},
key = {},
url = {https://arxiv.org/abs/2512.02058},
}