Curating corpora with classifiers: A case study of clean energy sentiment online
M. V. Arnold, P. S. Dodds, and C. M. Danforth
Times cited: 3
Abstract:
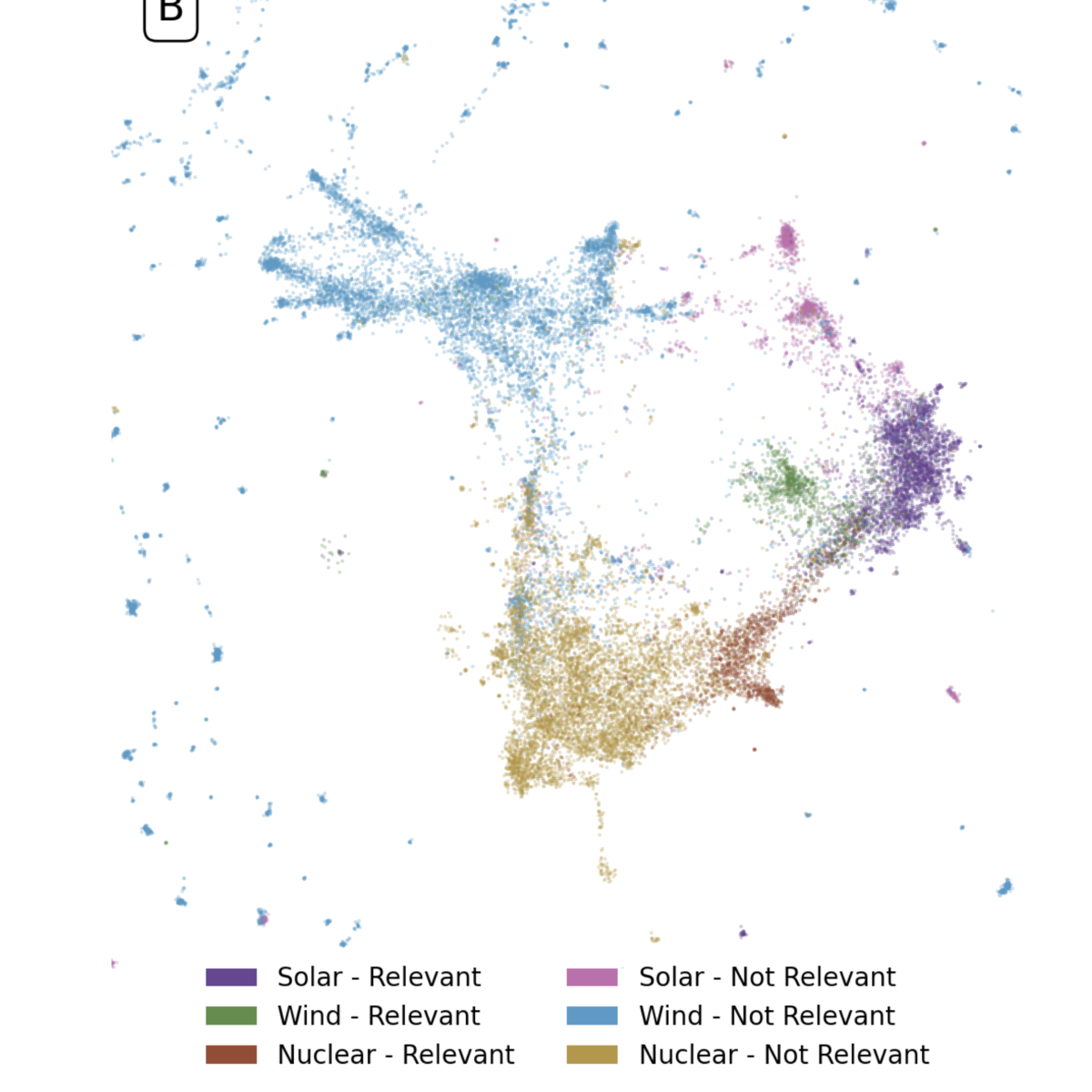
Well curated, large-scale corpora of social media posts containing broad public opinion offer an alternative data source to complement traditional surveys. While surveys are effective at collecting representative samples and are capable of achieving high accuracy, they can be both expensive to run and lag public opinion by days or weeks. Both of these drawbacks could be overcome with a real-time, high volume data stream and fast analysis pipeline. A central challenge in orchestrating such a data pipeline is devising an effective method for rapidly selecting the best corpus of relevant documents for analysis. Querying with keywords alone often includes irrelevant documents that are not easily disambiguated with bag-of-words natural language processing methods. Here, we explore methods of corpus curation to filter irrelevant tweets using pre-trained transformer-based models, fine-tuned for our binary classification task on hand-labeled tweets. We are able to achieve F1 scores of up to 0.95. The low cost and high performance of fine-tuning such a model suggests that our approach could be of broad benefit as a pre-processing step for social media datasets with uncertain corpus boundaries.
- This is the default HTML.
- You can replace it with your own.
- Include your own code without the HTML, Head, or Body tags.
BibTeX:
@misc{arnold2023a,
author = {Arnold, Michael V. and Dodds, Peter Sheridan and
Danforth, Christopher M.},
title = {Curating corpora with classifiers: A case study of
clean energy sentiment online},
year = {2023},
OPtpages = {},
note = {Available online at
\href{https://arxiv.org/abs/2305.03092}{https://arxiv.org/abs/2305.03092}},
}